



Gastbeitrag: Nur durch die Nutzung der Daten entsteht Wert; die IT ist gefordert, gut integrierte Technologien auf einer verwalteten Plattform bereitzustellen, sodass sich Mitarbeiter auf wertsteigernde Aufgaben konzentrieren können, fordert Andreas Juffinger.
 Foto: AWS
Der Autor Andreas Juffinger ist Senior Solutions Architect bei AWS
Foto: AWS
Der Autor Andreas Juffinger ist Senior Solutions Architect bei AWS
IDC und Forrester haben Untersuchungen veröffentlicht, in denen gezeigt wurde, dass Firmen, die mehr Daten nutzen, also datengetriebene Organisationen (DgO), schneller als der Mitbewerb wachsen. Richard Joyce, Senior Analyst bei Forrester schreibt, dass durch die Bereitstellung von 10 Prozent mehr Daten ein typisches Fortune 1000 Unternehmen über 50M Euro zusätzlichen Gewinn erreichen kann. Wie kann man das erreichen und eine DgO werden?
Erstens, ein DgO betrachtet Daten als einen Unternehmenswert und nicht als Eigentum von Abteilungen oder Geschäftszweigen. Der übliche Vergleich von Daten mit Öl steht der Demokratisierung der Daten im Weg, da dieses Bild die einzigartige Eigenschaft vom Betriebsmittel Daten verschleiert - man kann Daten weitergeben und sie trotzdem noch uneingeschränkt nutzen, sie verbrauchen sich nicht sondern je mehr man Daten nutzt, desto mehr hat man davon. Zweitens werden in DgO die gesammelten Daten im Bereich Analytics, Maschinelles Lernen und somit in Entscheidungsprozessen tatsächlich genutzt und nicht nur gesammelt. Aus den Daten werden komplexe Modelle, Abstraktionen oder Wahrscheinlichkeiten abgeleitet, die im Entscheidungsprozess unterstützen. Drittens ist in einer DgO sichergestellt, dass Daten im Unternehmen jederzeit einfach und sicher verfügbar sind, dafür braucht es eine entsprechende Daten- und Analyse-Plattform.
Viele Jahre lang war das Data Warehouse (DWH), eine für Analyse und Reporting optimierte zentrale Datenbank, der einzige Ansatz, eine solche Daten-Infrastruktur bereitzustellen. Ein DWH erfordert hohe Investitionen und ist primär für strukturierte Daten geeignet. Ein wesentlicher Teil der Daten im Unternehmen, die semi- und unstrukturierten Daten, bleiben somit aber unberücksichtigt. Big Data Plattformen erlauben es nun, strukturierte, semi- und unstrukturierte Daten wie Textdokumente und Bilder in einem sogenannten Data Lake, abzulegen. Der Data Lake wird somit das zentrale Repository für alle Daten, daher muss ein Data Lake es erlauben, Daten in beliebiger Skalierbarkeit zu speichern. Data Lakes basierend auf On-Premis Hadoop Ökosystemen sind sehr herausfordernd, benötigen hyper-spezialisierte Data Engineers und sind oft zu reinen Daten-Senken verkommen. Vor Jahren als das Allheilmittel angesehen, werden Data Lakes mittlerweile auch im Hype Cycle für Analytics und Business Intelligenz von Gartner im Tal der Ernüchterung positioniert.
Beide Generationen von Daten- und Analyse-Plattformen haben die Erwartungen vieler Unternehmen an eine agile und kosteneffiziente Dateninfrastruktur nicht erfüllt. IT-Abteilungen einer DgO sind gefordert, Fähigkeiten eines Data Lake, Maschinelles Lernen erfordert Rohdaten mit höchster Granularität, aber auch DWH, schnelle, komplexe Abfragen brauchen aggregierte Daten, bereitzustellen und aus den Fehlern der Vergangenheit zu lernen. Ein einheitlicher Ansatz führt letztendlich immer zu Kompromissen, der nur einen Teil der Business-Anforderungen abdecken kann.
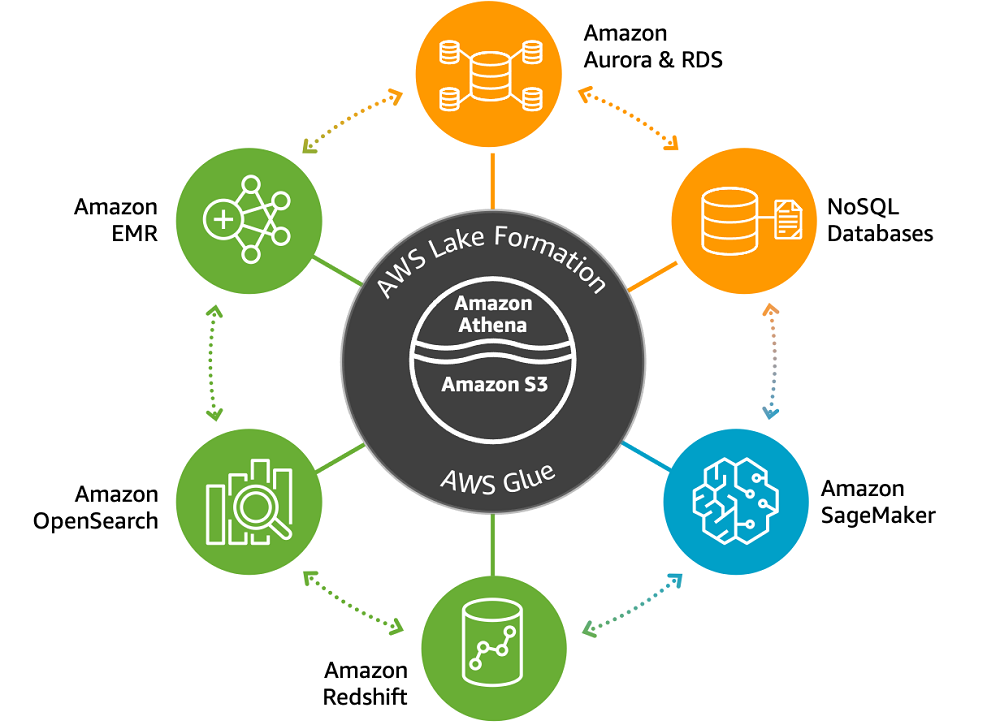 Foto: AWS
Amazons Lake-Haus Ansatz beschreibt die nahtlose Integration eines Data Lakes auf einer Plattform
Der Lake-Haus Ansatz
Foto: AWS
Amazons Lake-Haus Ansatz beschreibt die nahtlose Integration eines Data Lakes auf einer Plattform
Der Lake-Haus AnsatzAmazons Lake-Haus Ansatz beschreibt nun die nahtlose Integration eines Data Lakes basierend auf Amazon Simple Storage Service (Amazon S3), einem Data Warehouse (Amazon Redshift) aber auch Maschinelles Lernen mit Amazon SageMaker auf einer Plattform. Eine einheitliche Governance, ein Datenkatalog und voll integrierte ETL Dienste, wie AWS Glue, runden den Ansatz ab. Explorative Analytics wird mit Amazon Athena, dem interaktiven Abfragedienst, der die Analyse von Daten im S3 Data Lake mit Standard-SQL erlaubt, unterstützt.
Dieser Ansatz erlaubt nun die Datenbereitstellung für unterschiedliche Personas und Anwendungsfälle. Ein Data Scientist hat kann die Rohdaten in höchster Granularität nutzen, um damit Maschinelles Lernen zu betreiben. Data Engineers bereiten die Daten im Data Lake für Line of Business (LoB) Personas noch weiter auf und bereinigen, normalisieren diese zu den Level 2 oder aufbereiteten Daten. Wenn für Reporting komplexe Abfragen mit kurzen Antwortzeiten benötigt werden, können die Daten auch auf Level 3 oder als Strukturierte Daten ins DWH geladen werden. Ein LoB Nutzer kann nun die vorbereiteten Reports nutzen, aber auch mittels interaktiven Abfragen auf die aufbereiteten Daten oder Rohdaten zugreifen und der Data Lake wird somit zur zentralen Datendrehscheibe.
Der Lake-Haus-Ansatz erlaubt es nun, die unterschiedlichen Technologien gezielt einzusetzen, um Geschäftsanforderungen optimal zu erfüllen. Auch wenn ein solcher Ansatz im eigenen Rechenzentrum denkbar wäre, profitieren Organisationen hier von Cloud-Anbietern. Sie stellen nicht nur eine große Fülle von neuesten Technologien bereit, sondern Kunden können diese Technologien auch ganz in Abhängigkeit ihres jeweiligen Bedarfs nutzen, skalieren und auch wieder abstellen. Dabei fallen Vorabinvestitionen, wie sie beispielsweise im eigenen Rechenzentrum nötig sind, weg, denn bezahlt wird nach Verbrauch. Zudem können wertvolle IT-Ressourcen umverteilt werden, sodass sich IT-Spezialisten beispielsweise darum kümmern können, neue Innovationen voranzutreiben, statt sich um die Instandhaltung von Servern zu kümmern. Die technologischen Voraussetzungen um den Wandel zu einer datengetriebenen Organisation voranzutreiben, ob Großunternehmen oder Start-up, sind vorhanden, nun gilt es die ersten Schritte zu tun, um Silos aufzubrechen und vorhandene Daten im Unternehmen zu nutzen.
Dieser Artikel ist Teil unserer Serie "Cloud Computing im Fokus", die in den kommenden Wochen jeden Freitag auf www.ittbusiness.at erscheint.



_gross.jpg&size=390x230&crop=0&trim=1)



_gross.jpg&size=390x230&crop=0&trim=1)


